
Finding Bio Software Fit (BSF)
PMF in a small (but mighty) market


Bio Software Platforms are a mode of supercharging science, scientific workflows, and discovery processes across synbio, pharma, biotech, and biomanufacturing verticals. The universal issues with science, agnostic of vertical, are that we:
Do too much lab work, most of which is optimization
More bioinformatic analyses are needed than there are bioinformaticians
Compute costs can account for significant amounts of spend
Data security/biosecurity breaches are known to happen
Data harmonization and comparison with broader literature is difficult
Science collaboration and outsourcing isn’t streamlined
The upshot is that inputs are hard, fragile, and prone to failure as are the outputs. This is even worse than the ‘garbage in, garbage out’ adage because there’s multiple layers of issues which all could compoundingly distort outputs. In other words ‘garbage in, and 10x garbage out’. We don’t say this to be dismissive of all the hard work scientists toil over daily but more as a meta comment about science processes. Processes are the operative phrase here as ideally we don’t just work towards supercharging scientists but change how, where, and who does science (if you’re interested, check out this piece on the frontiers of bio automation). There are many ways to solve these problems: better robots, new life science technologies, and augmented software to help in the distribution and uptake of the new technology.
We’ve noticed with building bio software that targeting the right feature sets and user personas is a nebulous process and want to give clarity to founders starting to work here. We’ve noticed there’s very little writing about this topic, despite there being a surge of companies being formed in this area. So, we’re putting pen to paper to draft a methodology for finding Bio Software Fit (BSF). We hope BSF helps with clarity around the initial build and narrative process for companies being built here, much like this piece on platform disease fit (PDF) helps with platform therapeutics companies.

Why now?
Before we get into the details, we want to talk about the ‘why now’ for bio software. In the process of building and investing in areas and verticals, we give a lot of thought to inflection points. Inflections range from first order events (e.g. discovery of CRISPR, invention of PCR, next-generation sequencing) to aftershocks which result from a new understanding of markets we didn’t think existed. In the biology world, Benchling is the most salient example of the concept, purportedly generating at least $100M ARR (maybe more). Their path to value creation from a plasmid design company to full enterprise SaaS model is truly inspiring, and has led other operators and investors to think and iterate around similar models and markets. Benchling has also been a lightning rod for scientists appreciating and seeking out enhanced UI/UX experiences.
The market size dilemma
To give context, there are ~7,000 biotech, pharma, techbio companies between North America and Europe as compared to the >500,000 tech companies in the US alone. Bio is also encumbered by long sales cycles, a cultural reticence to change, and general disempowerment of the workforce to expense various tools. The upshot of the cultural differences in bio is low transaction frequency (months to years).
Given the material size difference in bio, software companies typically address many operations (Benchling does molecular biology tools AND electronic lab notebook AND lab information management systems). Besides wide feature sets, community building around platforms is becoming more common in bio software to encourage network effects and product-led growth. In the long-term, broadening the base of potential customers is essential.
To enable large bio software businesses, the market needs to keep expanding as transactions become more frequent with more funding and liquidity. This would allow ‘tech’ type pricing models from tiered software, freemium trials, free academic use, enterprise sales, and/or product-led growth. The decision points on sales strategy, pricing models, and market size, is in many ways deterministic based on the use case of the software. Because of this we highlight the use-cases we’ve seen could move the needle for folks in discovery research.
Choosing software use-cases
The following is a broad categorization of use cases that can be activated by valuable technology solutions. Categories span data analysis, bioinformatics pipeline/dev-ops tools, data management, reproducibility, lab automation, biosecurity and collaboration. We believe that the following markets provide growth potential for software solutions that enable the end user (you’ll find a more detailed breakdown of the various personas later in this article).
The largest group of use-cases is broadly around data analysis. While there is a long tail of assays that are used to interrogate questions in biology, we have proposed a simplified taxonomy that might help organize similar use cases and data analysis tasks that could be addressed by a single bioinformatics solution. Thinking in this way may help an entrepreneur find the largest addressable market without expending excessive resources and time on product development. Indeed, an expansion of data analysis is data contextualization and harmonization by comparing one’s own results with the corpus of literature and previously generated data in their field of research. This type of contextualization could allow for the discovery of unlikely trends or help understand the reproducibility of the system in question. However, any conclusions or discoveries that are output from any software platform, are only valuable if the inputs themselves can be trusted (providing motivation for focusing on automation and reproducibility in data generation). These use-cases are discussed in the table below, as is a new but salient use-case of the quantified self for biohackers. As biomarkers become cheaper (more here), we believe the amount of biomarker data people will be able to collect about themselves will outstrip their ability to analyze it, leading to another potential BSF use-case (and potentially larger addressable market size, as building a consumer facing business because more feasible with the success of this use case).
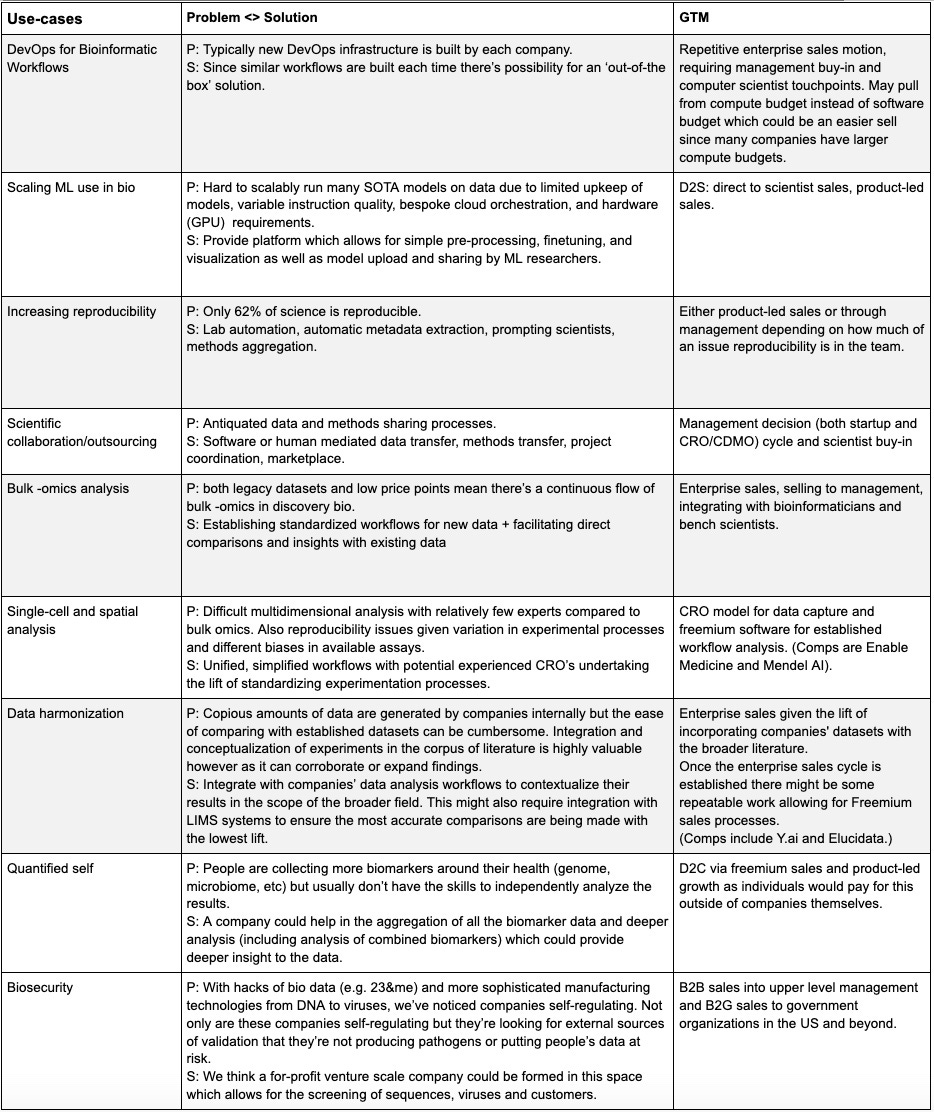
Breaking down the customers
End users (a.k.a. customers) can be broadly categorized into research and management. The use cases between these two groups typically differ.
For example, tools and workflows intended for research users might be more focused on empowering the analysis capabilities of the scientist, whereas management focused users might derive more value from summaries or meta analyses of experiments, progress towards goals, and coordination between teams).
Currently, many companies are employing undirected GTM strategies, but this dynamic will change as the market matures. Given these different personas, we believe that establishing a highly focused GTM strategy and offering a differentiated experience for management user group or in shared problems between the research and management teams will result in the best chance at success. There are some cases where this falls short where software additions could allow for productivity changes which could be used to sell to upper management.
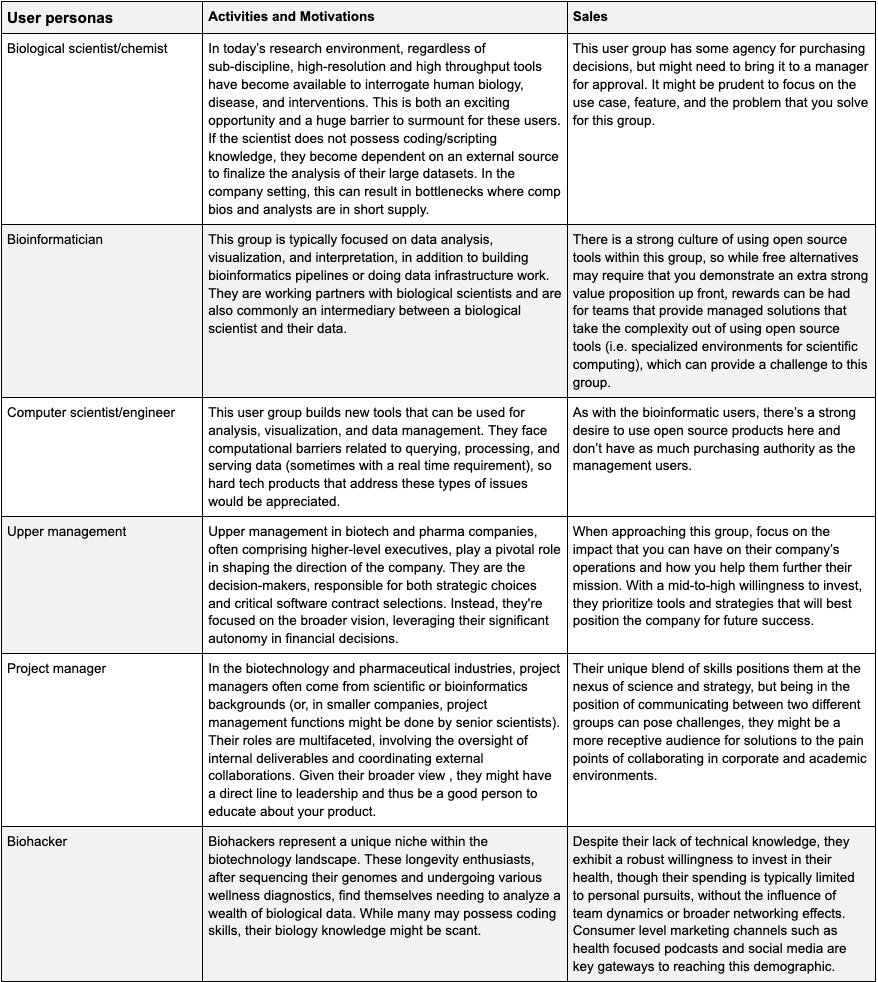
With the exception of the Biohacker persona, the other user types represent a familiar team structure in the biotech/pharma industry. While their individual motivations imply that different approaches/messages/channels are needed to successfully market a software product to each user segment, they are typically unified around a common goal and research platform. This is all to say that we can identify promising use cases where we see both 1) excruciating, unsolved problem and 2) a willingness by biotech/pharma companies (typically top-down) to invest in software solutions that enable new use cases in their respective verticals. Distinct motivations among these users mandate tailored marketing strategies, yet a unifying theme emerges: a shared objective and research paradigm.

Integrations
With more software solutions across the ecosystem from plasmid design to laboratory information management to electronic lab notebook, to data analysis workflows, integration and interoperability becomes a big question. Scispot has been the first we’ve seen to offer API integration with ELN and LIMs to create unified schema across various data types. We predict many more similar integrations will allow for greater interoperability between software platforms, but initially will help prevent customer attrition. However API integration will be part of the feature-set, not a use-case in and of itself.
Market penetration + conclusion
As mentioned above, the bio software space is small. Because of that, ways to broaden feature sets and tap into new customers is something of paramount importance. The need for new customers and network effects has manifested in community building conferences run by companies like Latch Bio or blogging by Cromatic. We believe that community building only makes sense once you have a product that solves core issues to scientists/companies.
Other ways of achieving market penetration is through increasing the founding team’s net promoter score (NPS). The Colabra team has done a fantastic job through their podcast Talking Biotech where they’ve interviewed over 400+ industry experts and garnered over 1.5M listens so far. Hosting hackathons, events, and even raves (!) are what some companies are using to pierce the collective consciousness. There is nuance here in understanding the person you’re marketing to and making sure they’re at the events you’re running. Founders need to be intellectually honest about this and realize if the direct customers aren’t there, it’s just wasted marketing.
So where can companies start, compete and eventually win in this ecosystem? This has to be a deeply personal synthesis of founders understanding their skills and interests and matching those to the highest needs areas in bio software (AKA founder-market-fit). Our intuition is that standard bioinformatics workflows (even if you have amazing experience here), aren’t the place to start. A core belief we have is that businesses are hard to build, so founders should build the most difficult (value accretive) version. For example, the analysis for SOTA analyses (single-cell and spatial-omics) hasn’t yet been productized to a degree which allows the widespread use of these techniques.
We suspect that as the environment evolves, the customers will become incentivized to adopt bio software solutions to address all aspects of their research and management workflows (a product adoption positive feedback loop). This selects for companies that provide and expand a suite of tools quickly. We see the speed of feature set expansion as a key for companies’ success in BSF. Again this connects to the first part of the article where there are compounding feedback loops in the uptake of new products, which is great because many layers of the stack need to be addressed to accelerate science.
Ultimately, we think the market is big enough to support a low single digit number of moderately large businesses ($100M+ ARR). A lot of uptake of bio software is due to the build or hire decisions companies will have to make in the upcoming years (especially with regard to biosecurity, more compute, productivity LLMs, and SOTA bioinformatic analyses). Ancillary verticals such as those related to the quantified self or biohacking are creating entirely new markets so the upside is less rigid but are predicated on societal trends (could be significantly more than $250M+ ARR). We also see real nuances between company positioning where companies which are grouped into compute budgets have higher revenue potential (due to higher compute budgets) than those that sell into scientists (which is part of software budgets). We also think many companies in discovery bio will expand feature sets and markets expanding into verticals such as the chemical and physics sectors to increase the TAM. However open questions remain about the size of the feature set needed to create minimal loveable products and what sales cycles and positioning create the best chance of success for a company in this space. Despite the difficulty of venture-scale businesses in software for discovery bio, scientists need better tools. We’re optimistic that tech-enabled scientists will have higher productivity and ultimately impact that can help cure disease and help the planet. It’s critical to understand how the scientist’s workflow is changing as this deeply influences innovation timelines.
Thanks to Maximilian Lombardo for working together on this piece. It’s been a pleasure to share insights and appreciate our collaboration.
Do reach out to Shelby (shelby[at]compound.vc) if you’re building here!
 | A guest post by
|
This is an awesome post--I'm trying not to subscribe to too many Techbio substacks but had to sub after reading this one 🫡
Thank you for this summary! Agree that API should/will be a norm in the features of bio software platforms, especially with more demands for automation. There are a few more layers to this - 1) appropriate granularity for proper data mapping, 2) clear documentation, 3) more data efficient options such as web hooks and 4) ongoing maintenance to ensure reliability. These are things that not all software platforms with APIs would offer. Our development team (disclosure: I work for SciNote ELN) spent time on these to make sure we don't just have an API, but the API works effectively. There will be more demands for platforms to offer APIs, and then the question will become whose API is better in quality - something that not enough people are asking just yet, but should and will soon.