The 'recalibration phase' of AI in drug discovery
Increasing the curative potential of the industry

AI in drug discovery has promised increased probability to success (PTS), efficiency in drug discovery, and cures for a wider range of diseases. A recent interview with Vineeta Agrawala of a16z suggested that AI-enabled drug discovery pipelines have decreased the time and money to investigational new drug (IND) applications from 6-10 years to 3-5 years. Although this may be true, there has been some negative press regarding the predictive validity of high-throughput platforms, ability of AI to inhabit new chemical space and over-concentration on preclinical throughput vs. clinical outcomes. Although these are valid points, I believe the critiques are symptomatic of the stage of AI in drug discovery rather than systemic issues.
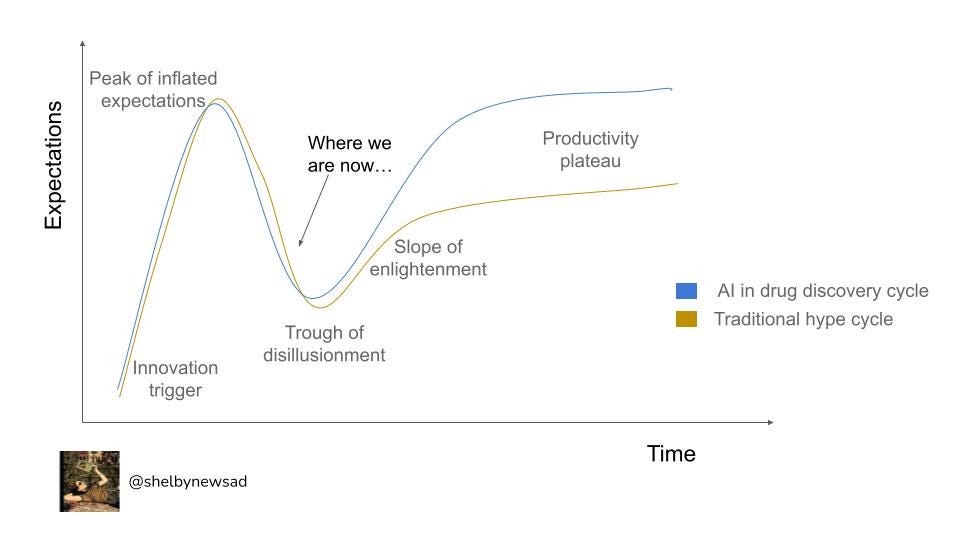
Every new innovation field goes through changes in sentiment, from machine learning to blockchain and artificial intelligence (AI) in drug discovery. Hype cycles were first coined by the advisory and information technology firm, Gartner and capture how expectations of technologies shift over time (below in black). I believe many of the issues have the potential to be addressed and will supersede the expectations of the traditional ‘productivity plateau’. The press recently regarding AI in drug discovery has been more critical than in previous years and I think this is a symptomatic ‘recalibration’ phase in the hype cycle and points out where I think we are in the industry.
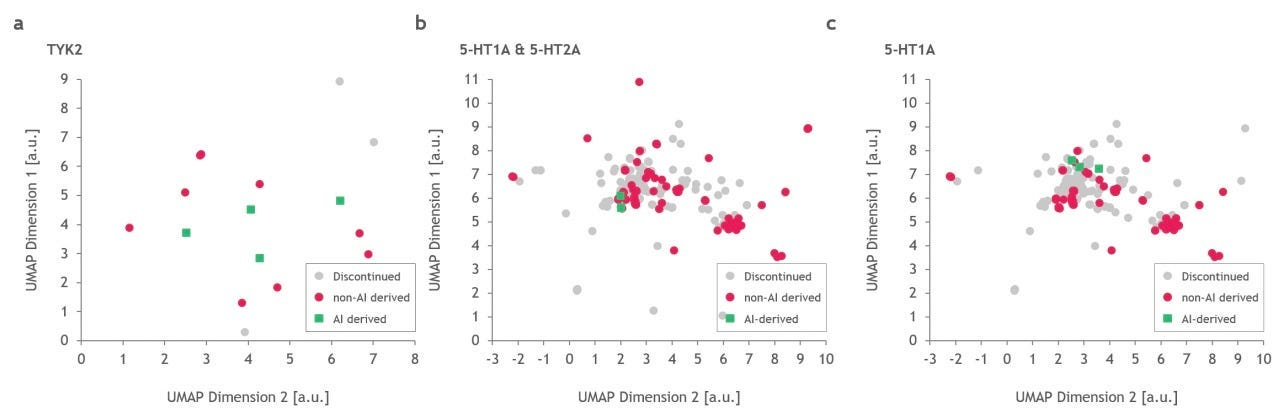
Problem: Recently, doubts have been cast on AI’s ability to find molecules that inhabit new novel chemical space from molecules previously described. This was discussed in November’s Decoding TechBio where they presented an article which displayed the similarities of Exscientia’s AI designed candidates to a drug, Haloperidol, which was approved by the FDA in 1967. Similarly, a paper in February of this year analyzed the chemical space of drugs created by AI-native companies, showing the same chemical space was inhabited by the molecules (their figure below). To some degree this makes sense because the models were likely trained on successful drugs for the corresponding targets. Drugs that inhabit the same chemical space of those previously approved have the added benefit of potentially similar toxicity and pharmacokinetics and pharmacodynamics (PK/PD) profiles. A real limitation of my comments are, of course, the swath of AI-discovered drugs that aren’t in the public domain. It will be interesting to see their chemical structure in the upcoming years and how they evolve with the field. Is what we’re seeing sample bias or is this a systemic issue due to the small number of approved/effective drugs we are training the algorithms on? However, the molecules inhabiting the same chemical space are clearly not living up to the expectations we had regarding AI in drug discovery - where ideally we would be finding more effective treatments by the models finding molecules outside the known chemical space.
Why it’s temporary: A way to get around this is to mine genomes and metabolomes for molecules which are outside of the chemical space of clinical-stage drugs.This is already being tackled by some early-stage techbio companies. Companies looking at metabolomic mining companies include Enveda and Brightseed. Other companies mining genomes such as Erebagen and Hexagon Bio to discover new molecules through understand pathways - which is also promising. These companies have the unique ability to find chemicals outside that which is known and move the whole industry forward in the process by allowing models to be trained on novel chemical space.
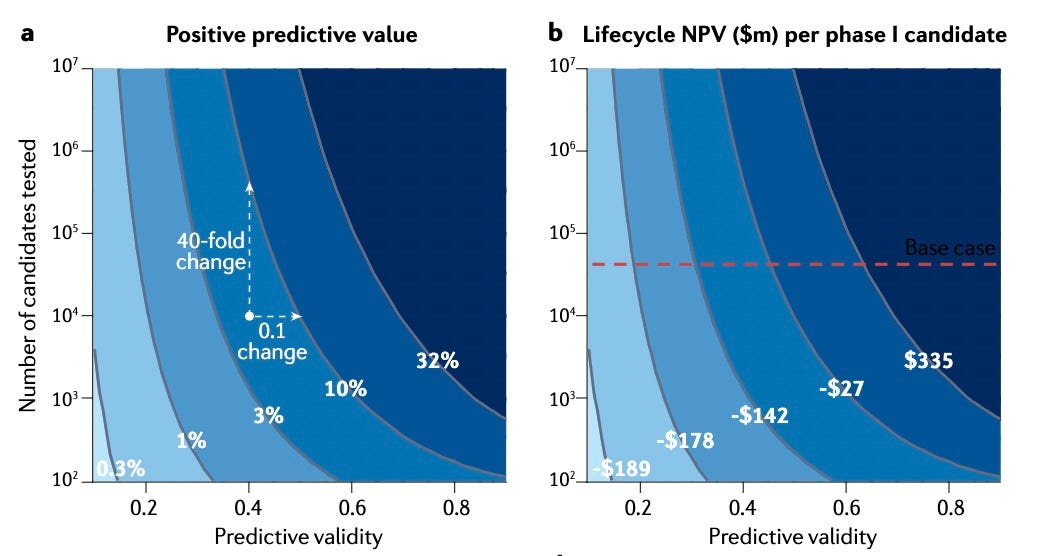
Problem: A recent article by the Eroom’s Law inventor, Jack Scannell et al., compares high-throughput methods for screening in low predictive disease models and low-throughput methods for screening in high disease predictive models. His analysis on the positive predictive value against the number of candidates selected shows the comparatively small effect of orders of magnitude more molecules compared to the predictive validity of the assay being used (a). Moreover, he highlights that seemingly trivial changes in predictive value (correlation coefficient changes from 0.5 to 0.6, for example) make more difference to clinical success than 10x-100x changes in molecules screened (also visualized in the figure below). In other words, the number of molecules screened matters most when you have a screen with high predictive validity.
Why it’s temporary: With the increased press around this article particularly and the dismal track record of drug approvals generally, more focus will be put on increasing predictive validity. Other improvements will encompass elucidation of modes of interaction as opposed to targets which harks back to predictive validity. Further, increased understanding of disease pathology will allow for more meaningful patient stratification, which has alone been shown to increase clinical trial success by 50%.
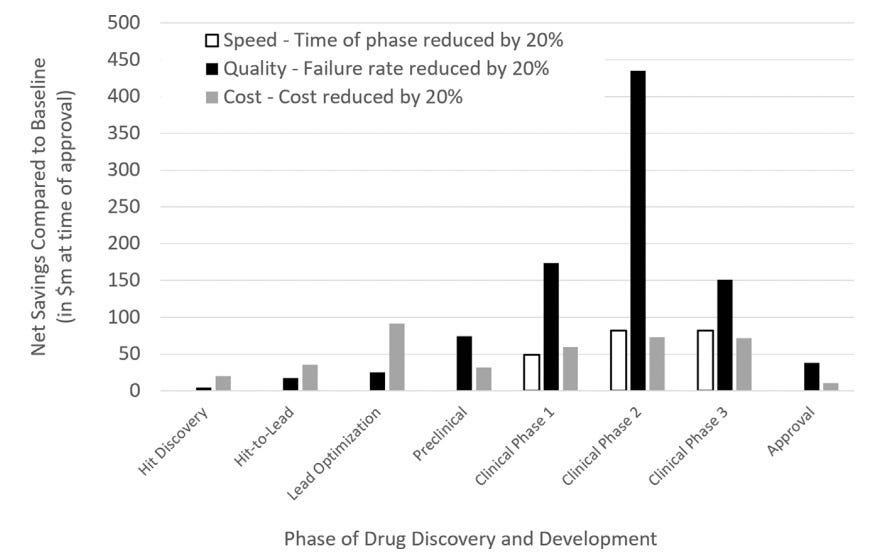
Problem: Another nuance to drug discovery is that cost savings matter the most in the clinic - especially in Phase II clinical trials. Brender and Cortés-Ciriano modeled in a recent article that cost, quality, and speed savings are most salient in the clinic, especially in Phase II clinical trials (figure below). Both of these views are somewhat at odds with the current state of the field where companies focusing on target discovery and target binding abound. I want to be clear to state that these are certainly necessary improvements and I’m glad it’s achieved so much interest. However, the current tendency is to focus primarily on target drugging and optimization and investigating the spectrum of properties later doesn’t take into account the massive influence that the entourage properties have. These other properties which pertain to in vivo activity (the highest cost driver!) are relegated to second tier importance. These properties include “…parent compounds, its metabolites, concentration-dependent effects…” physicochemical properties, PK/PD, secondary targets, and so on. Although some companies take ADMET (adsorption, distribution, metabolism, excretion, and toxicity) into account (7/20 AI-native companies chronicled in a recent Nature article), interestingly, the success programs encompassing ADMET testing will be able to be directly compared across the companies where we might be able to see differentiated success.
Why it’s temporary: I believe ADMET, especially ‘T’, or toxicity testing from earlier stages will have even greater importance attributed to it from the earliest stages. I believe there will be greater investor pushes to see all of these properties, especially if the differentiated success of the ADMET-testing becomes apparent. Specifically, more concerted measurements of cellular toxicity with human HepG2 cells will be undertaken as liver toxicity is a major reason for drug trial failures. I think understanding and screening around these properties will be a large part of the new drug discovery platforms. Innovation here will help in clinical success, although it may increase the time to clinic. This is a trade-off we all should be willing to take and is a tenant of organization effectiveness which promotes truth-seek over progression-seeking behavior.
Although this article has spoken a lot about what AI in drug discovery companies can do better, I also wanted to highlight exceptional strides being made in the field:
Beyond the amazing new research we’re seeing proven furthering of assets generated by AI-first therapeutics companies. AI-first Relay Therapeutics, Valo Health, Recursion Pharmaceuticals, Benevolent AI, Exscientia, and Insilico Medicine are now in the clinic. I’m very excited by the potential of AI programs in drug discovery and enthused that the current criticism will lead to concerted action in increasing the predictive validity of screens. I’m optimistic here and I think you should be too - do reach out if you’re working in this space.
Thanks to Mike Dempsey for your comments on this article.
People + tweets + reads you should watch here:






‘The modus operandi of drug R&D has long-been tailored to meeting the lowest bar necessary for an approval. The time to change this is finally upon us. Those of us working to build the next generation of therapeutics companies have a unique opportunity — in fact, a responsibility — to set a whole new bar for ourselves and our industry.’ - Guillermo Vela